Most "scale to $5K/day" posts hide the only part that matters: how the winning
creative was found before the budget got large.
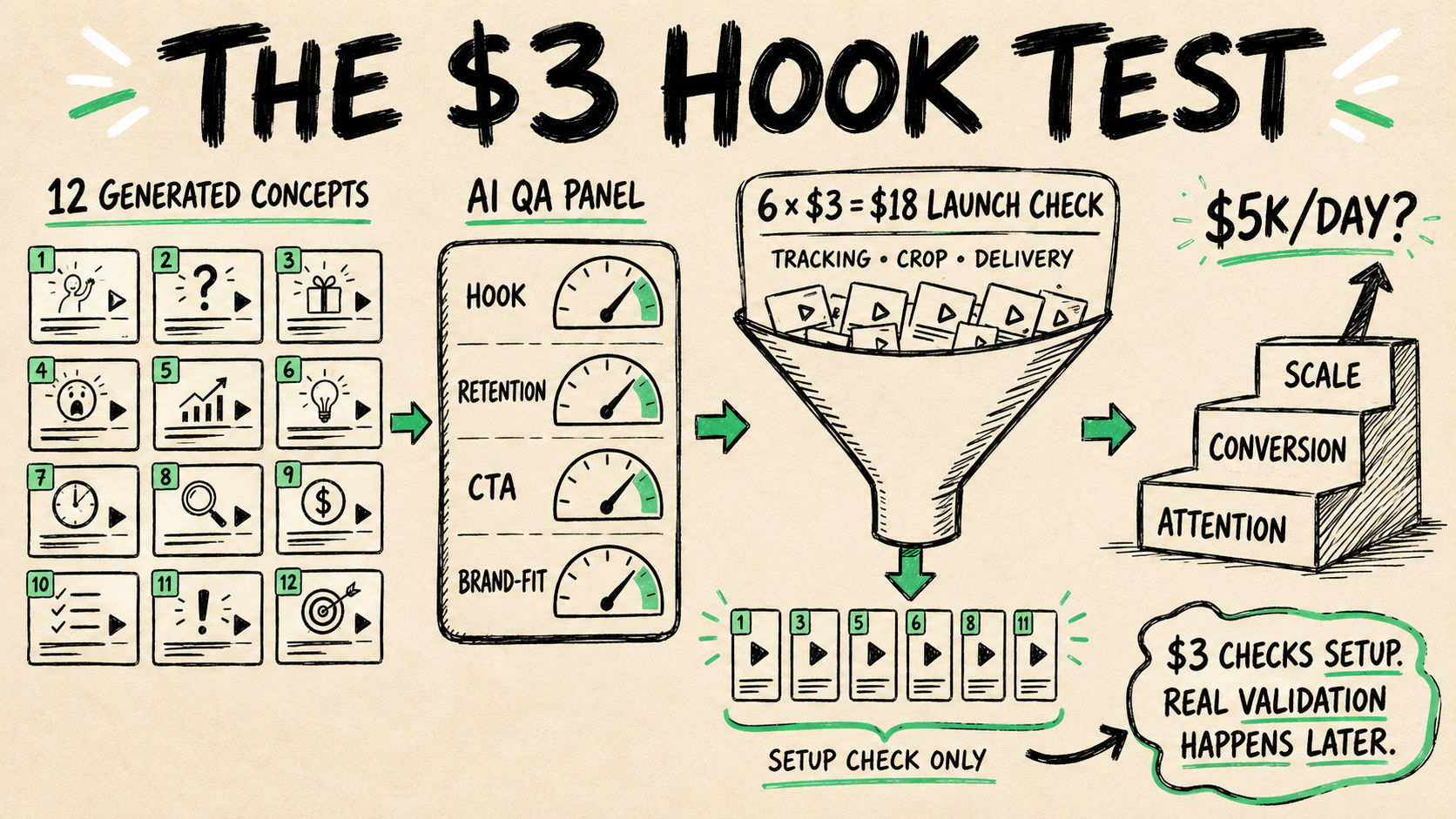
Here is the system I would use. Take one ordinary ecommerce product. Generate 12
different opening concepts without commissioning 12 shoots. Turn the best six
into controlled hook variants. Spend $3 per variant to catch broken delivery,
tracking, cropping, or landing-page issues. Then buy enough traffic to compare
attention—and enough conversions to judge whether the idea can sell.
TL;DR — Keep the product, offer, body, audience, and landing page fixed.
Change only the first 3–6 seconds. Use HeyDreaming
to turn one product URL into scored creative candidates, splice the best
openings onto one shared control body, then spend $3 per variant to verify that
the test is technically sound. Make performance decisions only after every
variant reaches a minimum sample. Scale the hook family that survives the
attention and conversion gates—not the prettiest AI render.
What does "$5K/day" require mathematically?
Start with the destination, because a revenue screenshot without unit economics
is decoration.
Here is a deliberately simple illustrative model for a generic $45 product:
| Input |
Example assumption |
| Average order value |
$45 |
| Revenue target |
$5,000/day |
| Orders required |
~111.1/day (~112 whole orders) |
| Target blended ROAS |
2.5× |
| Approximate ad spend |
$2,000/day |
| Target CPA |
$18 |
The math is 5,000 ÷ 45 ≈ 111.1 orders, 5,000 ÷ 2.5 = $2,000 in daily ad
spend, and $2,000 ÷ 111.1 ≈ $18 CPA. In practice, 112 whole orders would
produce $5,040 in revenue; the table models the $5,000 target rather than a
literal partial order. That does not prove the business is profitable.
Shipping, product
cost, payment fees, returns, taxes, discounts, and support still have to fit
inside the remaining contribution margin.
The point is to produce a real constraint: if the account cannot acquire an
order near the target CPA, no amount of "scaling" language fixes the economics.
Before testing creative, write down:
AOV:
Gross margin after fulfillment:
Target CPA:
Break-even ROAS:
Current landing-page conversion rate:
Daily loss limit:
If those fields are unknown, the first job is measurement—not more ads.
Why test the hook before the full ad?
The hook is the beginning of the video: the first visual, claim, question, or
pattern interrupt that earns the next second of attention.
TikTok's own creative guidance treats the first 3–6 seconds as the hook and
connects it to click-through and short-view metrics. Meta's creative A/B testing
also works by changing one creative variable while holding the rest of the test
stable. That is the principle here:
One product. One offer. One audience. One body. Twelve openings.
If every variation changes the avatar, price, claim, music, body copy, and CTA,
the test can produce a winner but cannot tell you why it won. The $3 framework
is useful only when the hook is the variable.
Step 1 — Build a 12-hook matrix, not 12 random scripts
I would start with six hook families and write two versions of each:
| Hook family |
Version A |
Version B |
| Pain |
"Still dealing with [pain] every morning?" |
"I was about to give up on [pain]." |
| Demonstration |
Show the product result before explaining it |
Split-screen: old method vs product |
| Contrarian |
"Stop buying [common alternative]." |
"The advice about [category] is backwards." |
| Specific proof |
"I tested this for seven days—here's what changed." |
Lead with a concrete review or result you can substantiate |
| Objection |
"I thought this was another gimmick too." |
"No, you don't need [expensive prerequisite]." |
| Identity |
"If you're a [specific buyer], watch this." |
"This is for people who are tired of [identity-linked pain]." |
The constraint matters more than the wording:
-
Every hook must connect to a fact on the product page.
-
No fabricated testimonials, countdowns, clinical claims, or before/after
results.
-
The product reveal, offer, body, CTA, duration, and landing page remain fixed.
-
Only the opening changes.
That gives you a real creative experiment instead of a folder of unrelated ads.
Step 2 — Generate 12 creative candidates with HeyDreaming
This is where HeyDreaming replaces the slowest part
of the loop.
- Paste the exact product-page URL—not the store homepage.
- Let HeyDreaming pull the product, logo, colors, fonts, and tone.
- Generate four distinct video cuts in about 90 seconds.
- Repeat for three runs to create a 12-concept batch.
- Treat the outputs as candidate openings and creative directions—not yet as a
controlled A/B test.
Use the matrix as a checklist, not a claim that three generic runs will
automatically cover all 12 cells. After each run:
- label each opening with its closest hook family;
- do not count duplicate ideas twice;
- manually rewrite the first 3–6 seconds or regenerate when a matrix cell is
missing;
- stop when you have 12 distinct concepts—or earlier if six strong, distinct
candidates already survive QA.
Every cut comes back scored on Hook, Retention, CTA, and Brand-fit. Export is
available in 9:16, 16:9, 1:1, and 4:5.
The score is not a validated prediction of CTR, CPA, or revenue. It is an
editorial QA checklist that makes weaknesses visible before export. I would use
it to flag:
-
openings that take too long to reveal the product;
-
logo-first or context-free intros;
-
strong openings attached to a dead middle;
-
videos that end without a clear next action;
-
generic renders that could belong to any brand.
Do not automatically launch the highest total score. For this experiment,
review Hook first, then check that Retention and CTA are not obviously
broken. A human still decides whether the claim is truthful, specific, and worth
testing.
Generate the concept pool → paste one product URL into HeyDreaming.
Use three four-cut runs to fill the 12-hook matrix, then bring only the strongest
six ideas into the controlled editing step below.
Step 3 — Turn the best six ideas into a controlled test
Use a relative shortlist, not an invented universal threshold.
| Decision |
Rule |
| Keep |
Relevant, specific, truthful opening with a clear product connection |
| Rewrite |
Strong idea, weak execution; opening is slow, vague, or disconnected |
| Reject before spend |
Misleading claim, broken crop, policy risk, or wrong brand/product |
This matters because generation volume can create a new problem: a larger pile
of guesses. Editorial QA should reduce the paid-test set, but it should not
pretend to identify market winners.
At this point, I would expect roughly six survivors.
Now make the comparison controlled:
- Pick one body section, product reveal, offer, CTA, duration, soundtrack, and
landing page.
- In CapCut, Premiere, or another editor, replace only the first 3–6 seconds
with each of the six candidate openings.
- Export all six in the same ratio and quality.
HeyDreaming supplies the creative candidates and QA dimensions. The editing
step—not the generation step—is what turns those candidates into a one-variable
experiment.
Step 4 — Run the $3 launch check
Now the deliberately small bet.
Give each surviving hook $3 of delivery under the same audience,
placement, optimization objective, schedule, and ad body. Because this stage is
technical rather than comparative, run the six checks as isolated ads or use
the two Meta-compatible batches defined in Step 5. Do not put six challengers
plus a control into one five-variant creative test.
At this gate, inspect systems—not winners:
| Check |
Question it answers |
| Delivery |
Did every variant receive impressions, or is the setup starving one? |
| Tracking |
Do clicks, UTMs, pixels, and conversion events appear correctly? |
| Render |
Is text readable and uncropped in the real placement? |
| Landing page |
Does the ad promise match the page, and does the page load? |
| Policy |
Did any variant trigger a rejection or warning? |
The rule that prevents self-deception
A $3 test cannot reject or certify a creative on performance.
At typical auction prices, $3 may buy only a few hundred impressions and a
handful of clicks. The cited operator case below contains the exact warning:
the operator said some ads were being killed after only $4–5 of spend;
separately, creatives that the old process would have killed at $8 later worked
after receiving $50–60.
Use three launch-check states:
-
Fix: broken tracking, crop, link, policy status, or landing-page mismatch.
-
Ready: technically sound and receiving delivery.
-
Inconclusive: thin or unequal delivery; keep running before judging.
Six hooks at $3 each means the first paid filter costs up to $18. The goal is
not to find—or eliminate—your scale ad for $18. The goal is to discover a broken
test before the broken test consumes a real budget.
Step 5 — Run two control-based attention batches
Meta's creative test supports up to five variants, so do not place six
challengers plus a control into one test.
Define the control before launch: your current best-performing opening on the
same shared body. If you do not have a historical winner, use a plain
product-first opening and label it CONTROL-V1. Render it fresh on the same
body and run it inside both batches; do not compare new candidates with old
historical metrics. Do not change the control between batches.
| Batch |
Variants |
Purpose |
| A |
Control + candidates H01–H04 |
Compare the first four hooks with the control |
| B |
Same control + candidates H05–H06 |
Compare the remaining two with the same reference |
The $18 covers only the six candidate launch checks. The control and all
attention-stage delivery are additional test spend.
For each batch, continue each variant until it reaches 1,000 impressions, 100
three-second views, and 20 outbound clicks—or spends one target CPA, whichever
comes first. These are directional event floors and a loss ceiling, not universal
sample-size requirements. If a variant hits the spend ceiling before the event
floors, mark it INSUFFICIENT, not a loser.
Budget accounting:
launch checks = 6 × $3 = $18
attention slots = 8 total (6 candidates + the control repeated in 2 batches)
attention ceiling = 8 × target CPA
worst-case fresh-test allocation = $18 + (8 × target CPA)
At the illustrative $18 target CPA, that is $18 + $144 = $162 before
conversion testing or reruns. If the six candidate launch-check ads carry
directly into the attention batches, their first $3 counts toward their
one-target-CPA ceilings.
Track:
| Metric |
Decision use |
| 3-second / 6-second view rate |
Did the opening earn more viewing? |
Hold rate (6s views ÷ 3s views) |
Did attention collapse immediately after the opening? |
| Outbound CTR |
Did the idea create click intent? |
| CPM |
Was delivery economics materially different? |
Compare each candidate only with the control in its own batch. Do not compare a
candidate in Batch A directly with one in Batch B, because the auction happened
at a different time. For CTR and hold rate, calculate a 95% confidence interval
for each proportion (a Wilson interval is safer than the simple normal
approximation at low event counts).
Use equal lifetime budgets per slot. Evaluate delivery when the batch median
spend first reaches 0.5 × target CPA, or at 72 hours if it never does.
Materially unequal means a slot has spent less than 70% of the batch median
at that checkpoint without a rejection, tracking failure, or having reached its
own event floor/ceiling. This is a spend-allocation validity check; the separate
>30% CPM rule below evaluates auction cost only after allocation is valid.
If median batch spend is still $0 at 72 hours, mark the whole batch INVALID.
Apply these rules in order; the first matching state wins:
- INVALID: the test was edited after launch, tracking broke, or delivery is
materially unequal by the rule above. Fix and rerun.
- INSUFFICIENT: the candidate hit one target CPA of spend before reaching
all event floors. Archive or retest under a cheaper traffic/video-view
objective; do not advance it to conversion testing.
- RETEST: CPM differs by more than 30% from its batch control, or either
metric's 95% interval overlaps the control's interval.
- REJECT: both the hold-rate and outbound-CTR intervals sit wholly below
the control's corresponding intervals.
- ADVANCE: both intervals sit wholly above the control's corresponding
intervals.
- MIXED: one metric is wholly above and the other wholly below. Rewrite or
retest; do not call it a winner.
Zero clicks before the event floor remain INSUFFICIENT; never convert a zero
into certainty without its denominator and interval.
If the control itself is INVALID or INSUFFICIENT, the entire batch is
non-comparable. Fix the setup or objective and rerun that batch.
The event floors do not create statistical significance. If two hooks are close,
keep both. For a higher-stakes account, use the platform's formal A/B test and
calculate sample size from the account's baseline rate and minimum detectable
lift before launch.
Step 6 — Give the survivors a real conversion test
The survivors now enter the expensive gate.
This stage is funded from your target CPA—not a universal daily budget. Keep the
one-variable discipline:
Define the rules before launch. Let T be target CPA, P purchases, and S
spend:
target_CPA = AOV ÷ target_ROAS
if P >= 20:
SCALE_CONFIRMED if CPA <= T
STOP otherwise
else if 10 <= P <= 19:
VALIDATED if CPA <= T; continue controlled scale toward 20
STOP otherwise
else if 5 <= P <= 9:
PROVISIONAL if CPA <= T; continue to 10 purchases
STOP if CPA > 1.25T
CONTINUE to 10 purchases if T < CPA <= 1.25T
else if 1 <= P <= 4:
CONTINUE if S < (P + 3)T
STOP if S >= (P + 3)T
else if P = 0:
CONTINUE if S < 3T
STOP if S >= 3T
For the illustrative $45 AOV and 2.5× target ROAS:
-
target CPA = $18;
-
zero-purchase stop = $54 per creative;
-
one purchase stops at $72 if no second purchase arrives; two stop at $90;
three at $108; four at $126;
-
at five to nine purchases, mark PROVISIONAL at or below $18 CPA, stop above
$22.50, and continue to ten purchases inside that band;
-
at ten to 19 purchases, mark VALIDATED and continue controlled scale only
when CPA is at or below $18;
-
at 20 purchases, mark SCALE_CONFIRMED only when CPA remains at or below $18.
Why three times target CPA? If the creative were truly converting at the $18
target, $54 of spend represents roughly three expected purchases; under a rough
Poisson model, observing zero has about a 5% probability (e^-3). Real auctions
are not perfectly stable or independent, so treat this as a pragmatic loss
limit—not a theorem. The (P + 3)T rule for one to four purchases applies the
same three-expected-purchase buffer after crediting the purchases already seen.
These are operational loss controls and promotion gates, not proof of causal
lift. If your account cannot tolerate those test losses, test fewer variants.
Do not edit the ad every few hours. Meta explicitly describes a learning phase
in which delivery is still exploring, and significant edits can disrupt that
process. Set a loss limit in advance, then let the test reach it.
The decision hierarchy:
- Can it hold attention?
- Can it create qualified clicks?
- Can the page convert those clicks near target CPA?
- Can performance survive more spend?
This is where a hook graduates from "interesting" to "commercially useful."
Step 7 — Scale the hook family, not one fragile video
Suppose the winning opening is:
"I thought this was another gimmick—then I tried it for a week."
The wrong response is to pour the entire budget into that one file until
fatigue kills it.
The right response is to treat the winner as a hook family and make controlled
extensions:
-
same line, different first visual;
-
same objection, different speaker;
-
same opening, different proof in the middle;
-
same mechanism, different customer segment;
-
same script, native 9:16 and 4:5 executions.
Run those extensions through the same HeyDreaming QA → $3 launch check → minimum-
sample attention test → conversion test sequence. You are building a
replenishable creative system, not hunting for one immortal ad.
Step 8 — Use a promotion ladder
The framework becomes easier to operate when every creative has a state:
IDEA
↓ product-truth check
GENERATED
↓ HeyDreaming Hook/Retention/CTA/Brand-fit editorial QA
CONTROLLED VARIANTS
↓ splice each opening onto one shared body
$3 LAUNCH CHECK
↓ delivery / tracking / crop / page / policy only
ATTENTION TEST
↓ Batch A: control + 4; Batch B: same control + 2
CONVERSION TEST
↓ target-CPA loss controls + purchase gate
SCALE
↓ confirm the hook family over ≥20 purchases
ARCHIVE / ITERATE
No ad skips a gate. No dead idea receives a production budget because someone
on the team likes it.
What would the tracking sheet look like?
Copy this structure into Sheets or Notion:
Test setup
| Batch |
Control ID |
Objective |
Target CPA |
Attention ceiling/slot |
Median-spend checkpoint |
Started |
Last edit |
| A |
CTRL-A |
|
|
|
0.5T |
|
|
| B |
CTRL-B |
|
|
|
0.5T |
|
|
Creative QA and validity
| ID |
Batch |
Control? |
Family |
Opening |
QA Hook |
QA Ret. |
QA CTA |
QA Brand-fit |
Launch QA |
Tracking valid? |
Edited after launch? |
Delivery spend/median |
Validity reason |
| CTRL-A |
A |
Yes |
Control |
Product-first control |
|
|
|
|
READY |
Yes |
No |
|
|
| H01 |
A |
No |
Pain |
"Still dealing with…" |
|
|
|
|
READY |
Yes |
No |
|
|
| CTRL-B |
B |
Yes |
Control |
Same control opening |
|
|
|
|
READY |
Yes |
No |
|
|
| H05 |
B |
No |
Objection |
"I thought this…" |
|
|
|
|
READY |
Yes |
No |
|
|
Paid results and decision
| ID |
Spend |
Spend ceiling |
Impr. |
3s |
6s |
Outbound clicks |
CPM |
CPM Δ vs control |
Hold CI relation |
CTR CI relation |
Purch. |
CPA |
Stage |
State |
Decision time |
| CTRL-A |
|
|
|
|
|
|
|
|
reference |
reference |
|
|
attention |
|
|
| H01 |
|
|
|
|
|
|
|
|
|
|
|
|
attention |
|
|
| CTRL-B |
|
|
|
|
|
|
|
|
reference |
reference |
|
|
attention |
|
|
| H05 |
|
|
|
|
|
|
|
|
|
|
|
|
attention |
|
|
The sheet creates a feedback loop:
-
Which hook families repeatedly score well but fail in-market?
-
Which low-production visuals produce the best clicks?
-
Which winning hooks collapse on the landing page?
-
Which concepts have earned a higher-production creator remake?
That last question is the economic point of the framework: use cheap AI
creative to decide which concept has earned expensive production.
Where does this framework fail?
It fails when the operator asks creative to solve an upstream problem.
The offer is weak
A better opening cannot rescue an undifferentiated product at the wrong price.
The landing page leaks
High CTR plus low conversion often means the ad created interest that the page
could not close—or the hook made a promise the page did not support.
The audience is wrong
A precise test shown to the wrong people produces precise-looking noise.
The sample is tiny
The $3 stage is intentionally non-decisive. Treating it as a profitability or
attention test is the fastest way to kill a good idea or crown a random one.
The score becomes an oracle
HeyDreaming's scores are editorial QA prompts, not paid-performance predictions.
They can flag structural issues worth reviewing; the ad platform and checkout
remain the judges.
Is the $3 Hook-Testing Framework worth trying?
Use it if your current process looks like this:
- pay a creator or editor for one UGC concept;
- wait days for delivery;
- run it;
- discover the opening was weak;
- repeat.
The alternative is to test the idea hierarchy before the production hierarchy:
-
generate 12;
-
pre-screen six;
-
spend $18 to verify six tests are technically sound;
-
buy a minimum attention sample, then properly validate the survivors;
-
remake and scale the hook family that survives.
That will not magically create a $5K/day store. It gives you a disciplined way
to search for the creative capable of supporting one—without paying full price
for every guess.
Build your first 12-hook batch → heydreaming.com
Paste one product URL, get four scored ad-video candidates per run, and build the
opening concepts for a controlled paid test before you commission the final shoot.
Sources and further reading